« February 2006 | Main | April 2006 »
2006-03-24
Optimizing, finally...
The good thing about working with large datasets is that it makes you want to optimize your code...
Today, I rewrote Wilbur's triple store indexing code, and load speed went from 2200 triples/sec to 2600 triples/sec (on my 1.67 MHz Powerbook). Also query performance was improved.
Posted by ora at 00:01 | Comments (2)
2006-03-23
Bigger Datasets
I have just experimented with a dataset of about 2 million triples in Wilbur's main-memory triple store (again enzyme, protein and gene data) and browsed it with OINK. I used a 1.67MHz Powerbook G4; on this machine, Wilbur loads and parses triples from the RDF/XML-formatted file at the speed of about 2200 triples/sec (still largely unoptimized code, running on OpenMCL). It took about 15 minutes to load about 150MB of RDF.
From the viewpoint of a human user browsing data, performance was quite comfortable, although it seems that at times the reasoner hogs 80-90% of the CPU... The data has pretty deep subclass hierarchies, multiple direct superclasses for many classes, and lots of domain and range definitions for properties.
It may be time to measure the query engine's and reasoner's performance. I think the indexing of the triple store could be improved, but I need to figure out what the dominant (low-level) query patterns are.
Posted by ora at 05:55
2006-03-20
OINK
I have been working on an "RDF browser", built using Wilbur. I am tired of looking RDF data in the RDF/XML (or any other syntactic) form. It seems that an RDF graph can easily be rendered as hypertext, and browsing is a very intuitive way to navigate data. Loading multiple RDF documents into Wilbur's triple-store and viewing them all together offers a simple way to integrate data, ad hoc. I've dubbed this piece of software "OINK" for "Open Integration of Networked Knowledge" (really).
All that OINK really knows is the RDF metamodel. It has no knowledge of any schemata, although the architecture allows "special" rendering of instances on a class-by-class basis. Because OINK is built on top of Wilbur, each triple, when visualized, also offers information about its provenance. "Actual" triples are visualized differently from entailed triples. Nodes are identified by their URI, QName or (if it exists) value of the rdfs:label property (or any subproperty thereof). Browsing data that's based on a "correctly" constructed schema will not reveal any URIs or QNames to the user.
OINK uses the Portable Allegroserve HTTP server as its "application platform"; otherwise OINK is just a thin layer on top of the basic Wilbur API. Current implementation is less that 1000 lines of code (in Common Lisp).
As an experimental feature, the paths that the user takes through an RDF graph can be automatically treated as queries (in WilburQL path query language). This allows one to quickly find similarily related objects. Queries can be named; these names are subsequently treated as RDF properties, "rewritten" on the fly, and query results visualized as the values of (repeated) properties.
Using OINK seems to be very addictive. I have just been browsing about 500,000 triples worth of enzyme, protein and gene ontology data. Way cool, even if I don't understand anything about the subject matter. :-)
Here's a sample OINK page, browsing the RSS 1.0 feed of this blog:
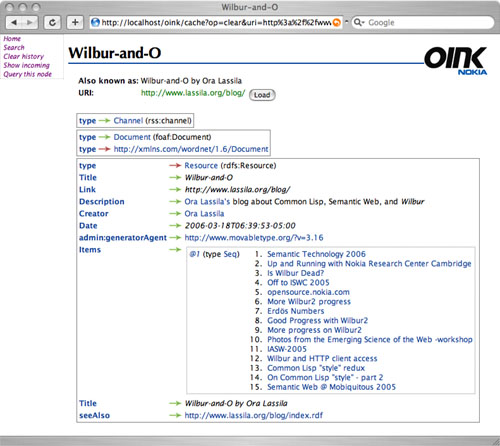
Posted by ora at 22:41 | Comments (5)
2006-03-18
Semantic Technology 2006
The Semantic Technology 2006 conference was held last week in San Jose, CA. The event was bigger than I expected, with at least 600 people participating. With a price tag of up to $1795 just for the conference registration, this is pretty good.
I gave the keynote speech together with Jim Hendler; this was a fun experiment, since it required us to not only agree on what we were going to say, but also who was going to say what. A PDF version of our slides is available (warning, it is a rather large file, 4MB or so).
I was excited to see so much commercial activity (startups, product announcements, etc.). In my mind, Oracle's announcement of their RDF Data Model support continues to be the big news item of this industry. Not that there haven't been persistent and scalable triple store solutions before, but this is a major mainstrean IT vendor openly announcing that they are "doing the Semantic Web". I think this is what many of us who have been around in the Semantic Web community for awhile have really been waiting for.
Posted by ora at 06:39 | Comments (5)